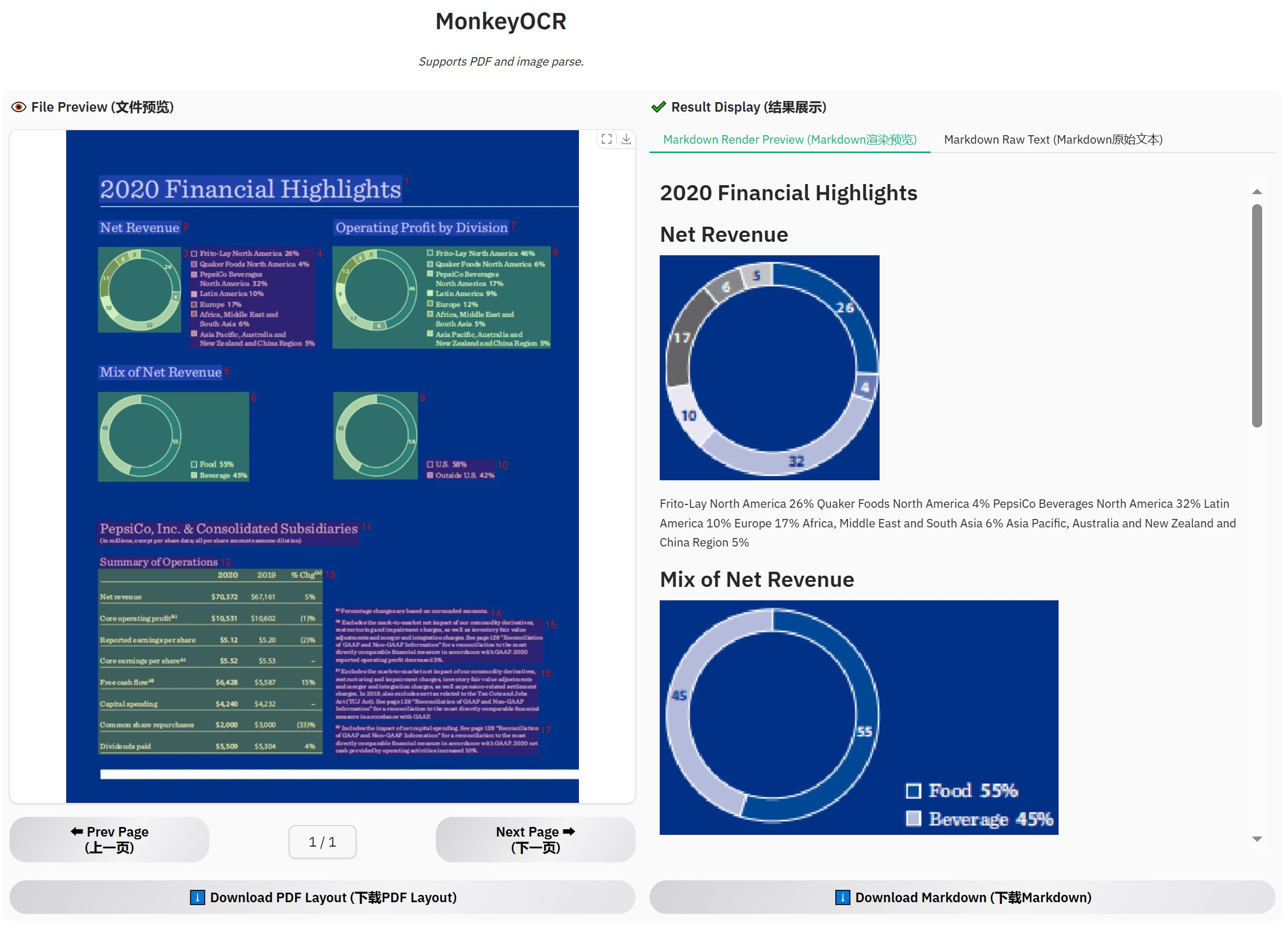
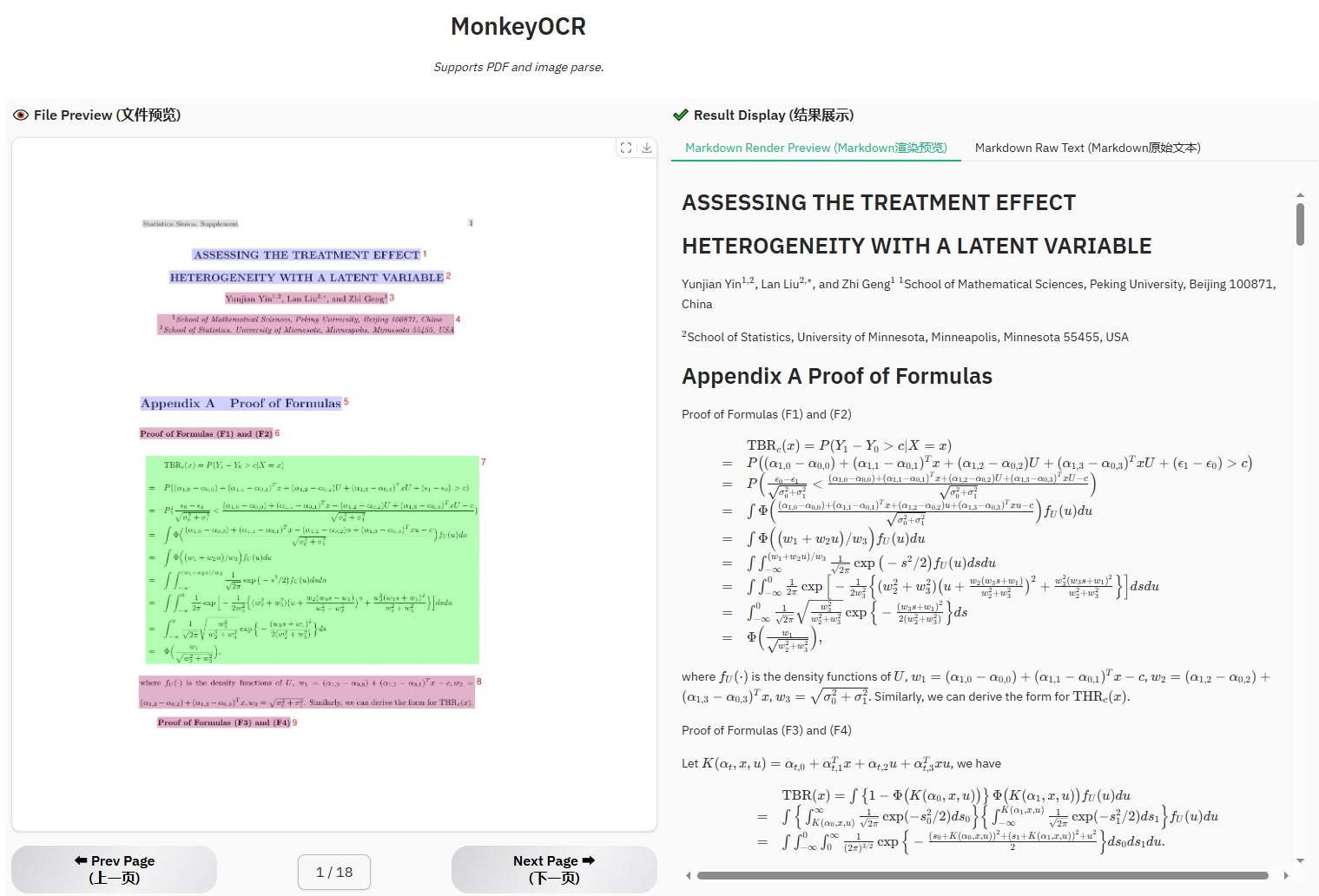
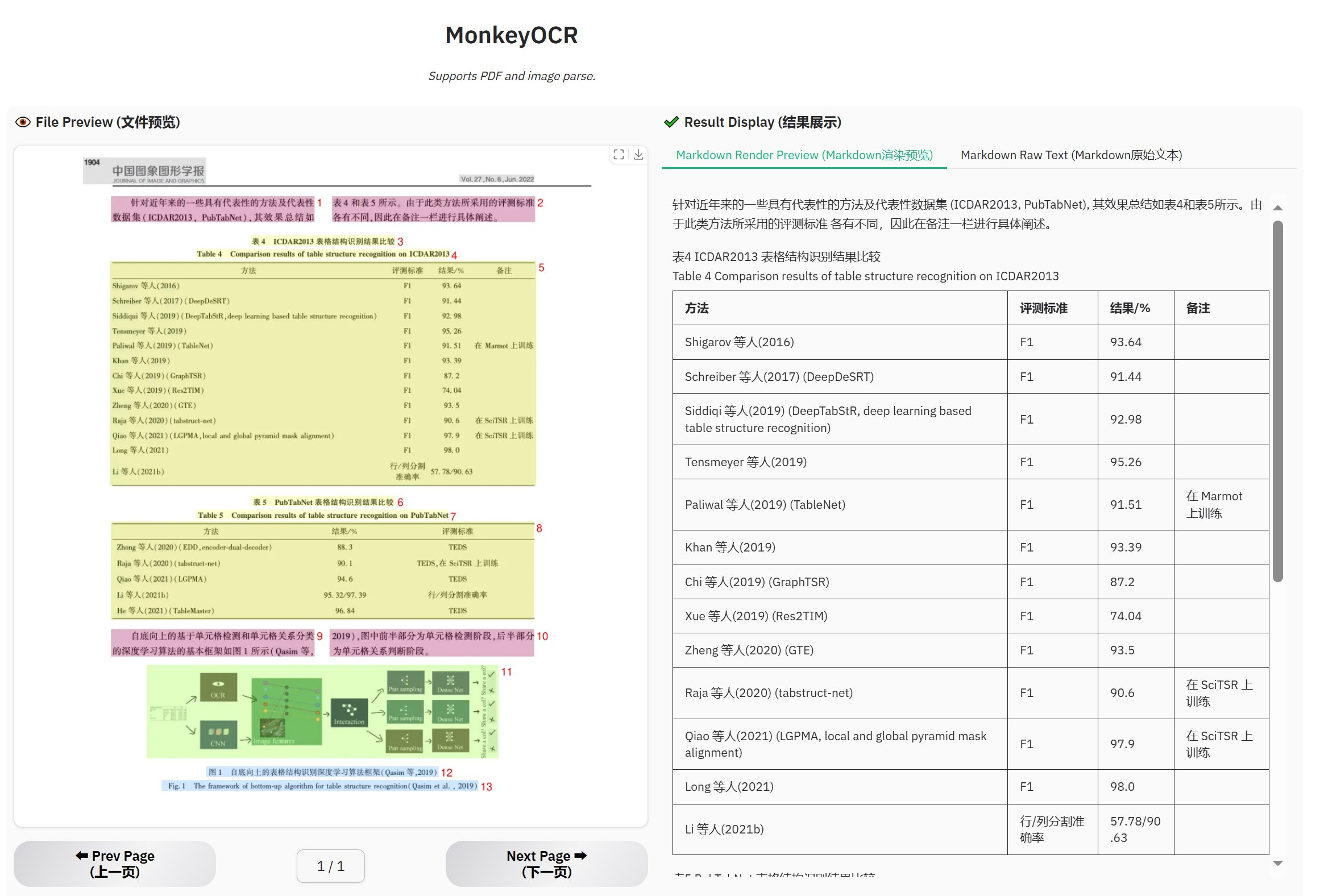

在 X 上看到大佬强烈推荐 MonkeyOCR,准备一试究竟,正好项目中也需要在全面数字化的过程中使用 OCR 来降低实验室工作人员的负荷,尽可能让她们保持和原来相同的工作方式。另外生产岗位上还有不少工人也还没有IT技能或是不具备这样的环境。
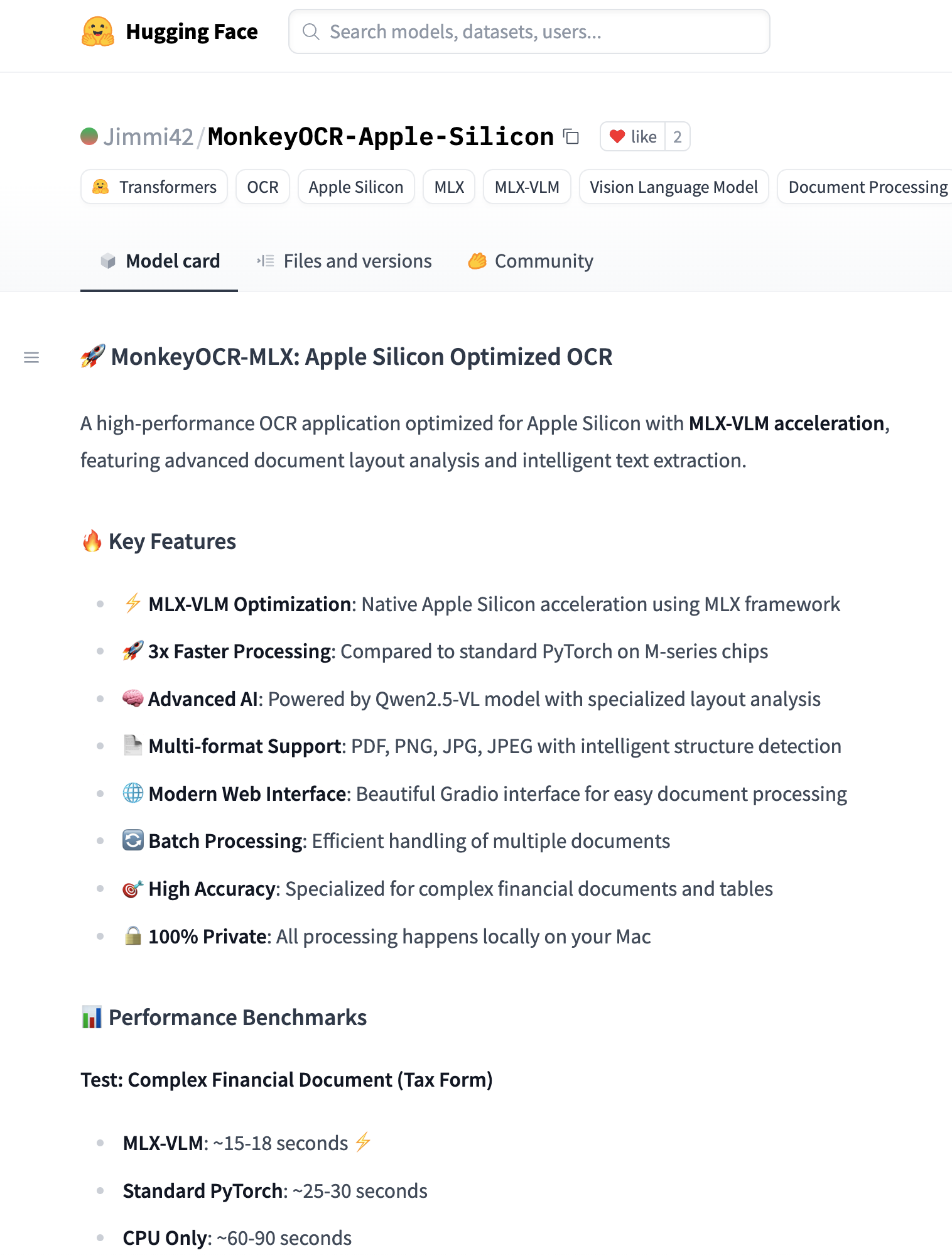
第一步就卡住了,在conda 环境中安装 torch的时候发现对应的torch版本是需要 CUDA 环境的,我在 M1 Max 显然解决不了这个问题。这个时候万事不决问 AI 的方法显现效果,推荐了项目: MonkeyOCR-Apple-Silicon
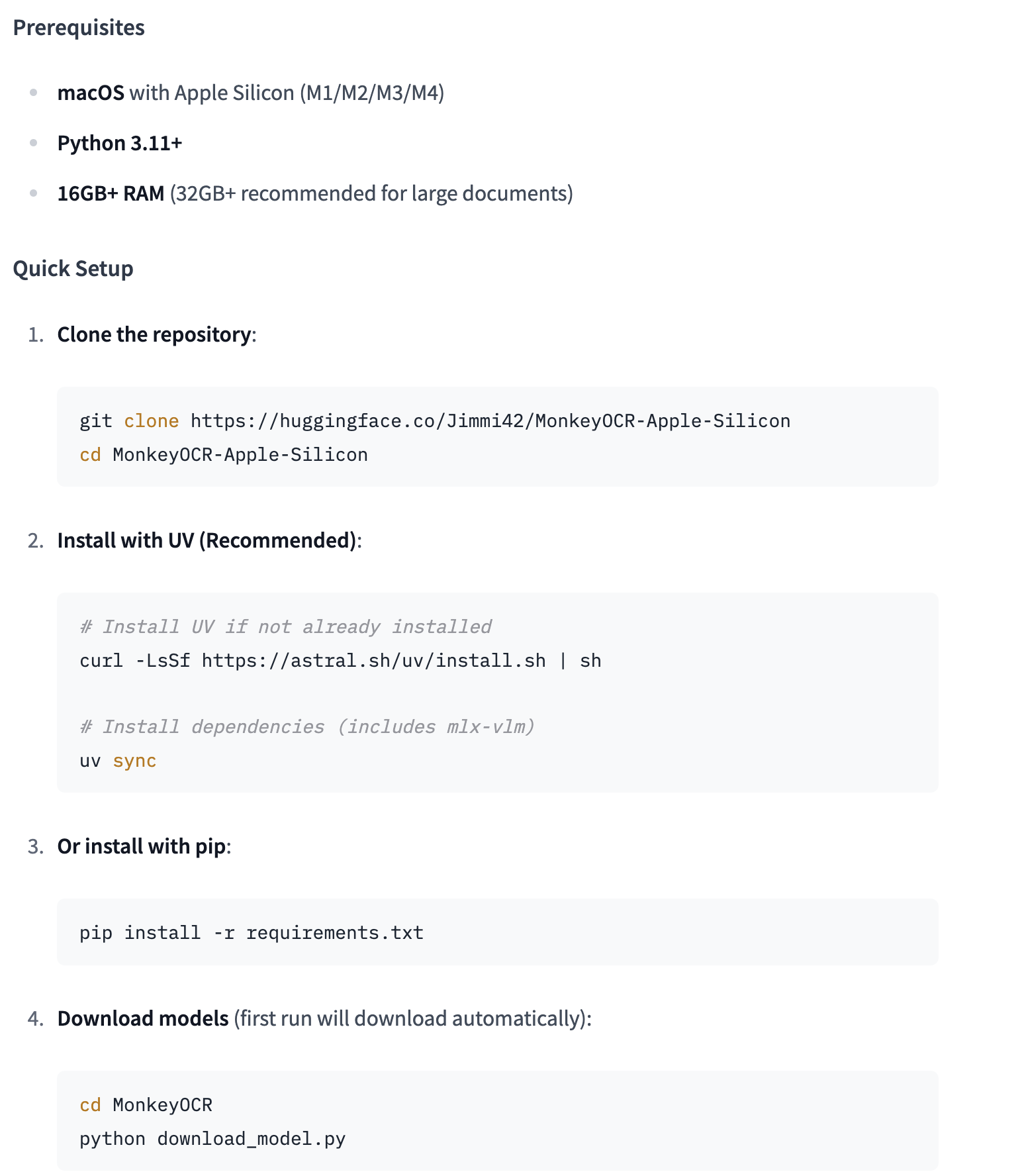
不过该项目原文中有一个地方挺让人 confuse
|
|
WTF,我的 MonkeyOCR-Apple-Silicon 目录下并没有另外一个 MonkeyOCR 目录,经过浅浅思索,在原项目:MonkeyOCR 的 tools 目录下是有 download_model.py 的,原来这个项目也还是有用的。
经过漫长的时间等待下载(是的,网络拉垮,还在等待中……),我相信胜利是属于我的。